HBase
HBase
概述
Apache HBase™ 是 以 hdfs为数据存储的 ,一种分布式、可扩展的 NoSQL数据库。
数据模型
HBase的设计理念依据 Google的 BigTable论文,
- 论文中对于数据模型的首句介绍:Bigtable 是一个 稀疏的 、 分布式的 、 持久的 多维排序 map
- 之后对于映射的解释如下:该映射由行键、列键和 时间戳索引;映射中的每个值都是一个未解释的字节数组(未序列化的)
- 最终 HBase关于 数据模型和 BigTable的对应关系如下:
- HBase 使用与 Bigtable 非常相似的数据模型。
- 用户将数据行存储在带标签的表中。
- 数据行具有可排序的键和任意数量的列。
- 该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。
逻辑结构
存储数据稀疏,数据存储多维,不同的行具有不同的列。
数据存储整体有序,按照RowKey的字典序排列,RowKey为Byte数组
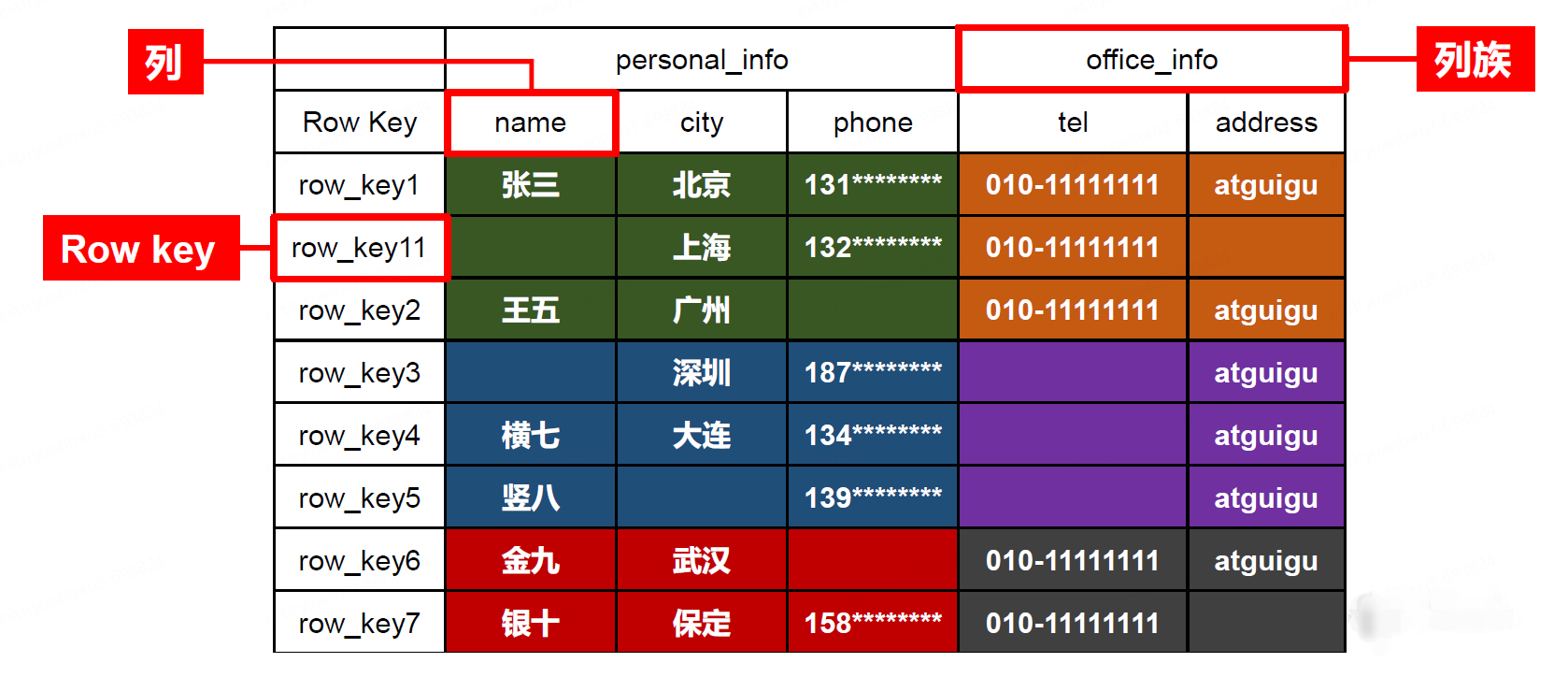
存储结构
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不存储
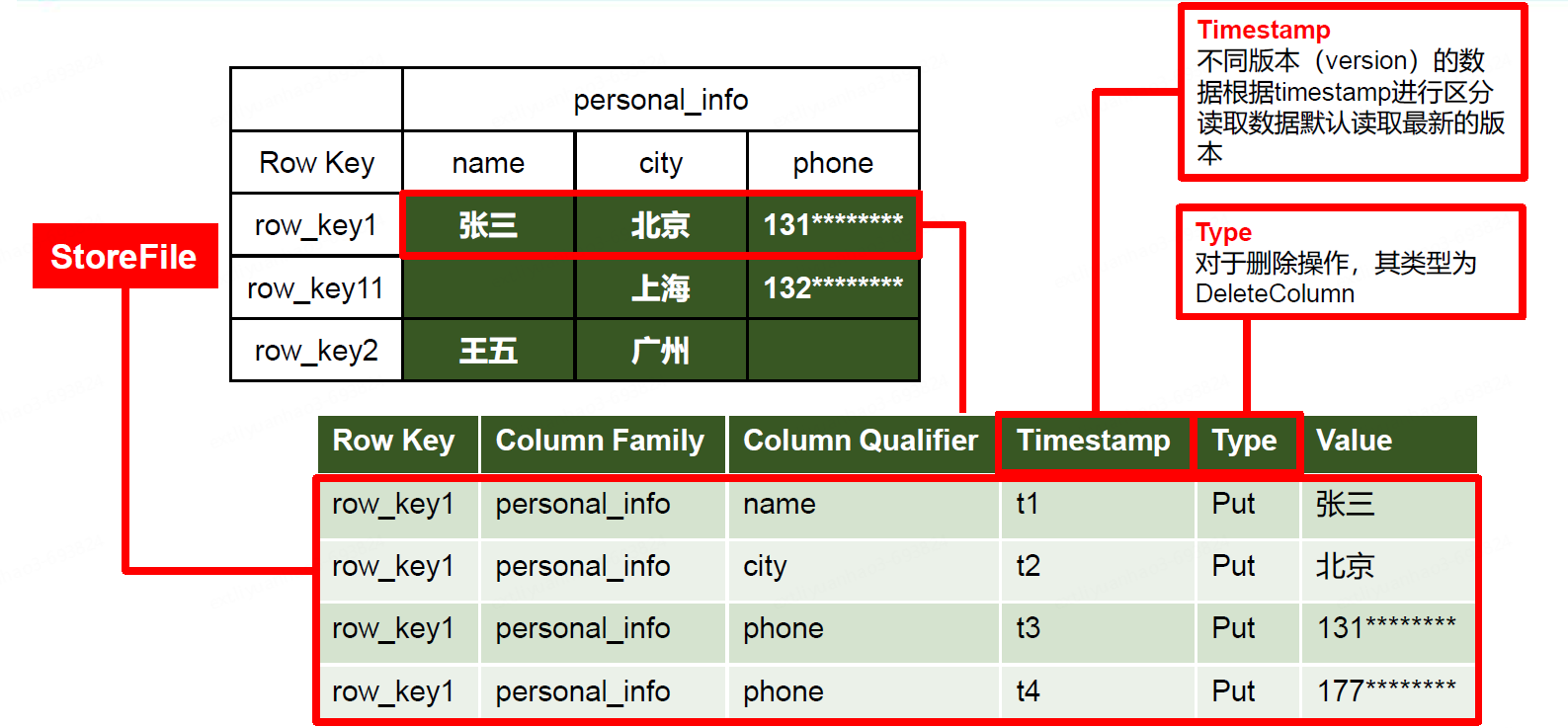
数据模型
NameSpace:命名空间,类似于关系型数据库的database 概念,每个命名空间下有多个表。
- HBase 两个自带的命名空间,分别是hbase 和default,
- hbase 中存放的是HBase 内置的表,
- default表是用户默认使用的命名空间
Table:类似于关系型数据库的表概念。
- 不同的是, HBase 定义表时只需要声明列族即可,不需要声明具体的列。
- 因为数据存储时稀疏的 所有 往 HBase 写入数据时,字段 可以 动态 、 按需指定 。
- 因此,和关系型数据库相比, HBase 能够轻松应对字段变更的场景。
Row:表中的每行数据 都由一个 RowKey 和多个 Column (列)组成,
- 数据是按照 RowKey的字典顺序存储的 ,
- 并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
Column:每个列都由 Column Family 列族 和 Column Qualifier (列限定符) 进行限定 ,
- 例如 info name info age 。建表时,只需指明列族,而列限定符无需预先定义。
TimeStamp:用于标识数据的不同版本(version )
- 每条数据写入时,系统会自动为其加上该字段,其值为写入 HBase 的时间。
Cell:由{rowkey, column Family column Qualifier, timestamp} 唯一确定的单元。
- cell中的数据全部是字节码形式存贮
基本架构
Master:实现类为HMaster,负责监控集群中所有的 RegionServer 实例。主要作用如下:
- 管理元数据表格hbase:meta,接收用户对表格创建修改删除的命令并执行
- 监控region 是否需要进行负载均衡,故障转移和region 的拆分
- 通过启动多个线程监控实现
- LoadBalancer 负载均衡器:周期性监控region 分布在regionServer 上面是否均衡,由参数hbase.balancer.period 控制周期时间,默认5 分钟
- CatalogJanitor 元数据管理器:定期检查和清理hbase:meta 中的数据。
- MasterProcWAL master 预写日志处理器:把master 需要执行的任务记录到预写日志WAL 中,如果master 宕机,让backupMaster读取日志继续干
RegionServer:Region Server 实现类为HRegionServer,主要作用如下:
- 负责数据cell 的处理,例如写入数据put,查询数据get 等
- 拆分合并region 的实际执行者,有master 监控,有regionServer 执行。
Zookeeper:HBase通过 Zookeeper来做 master的高可用、 记录 RegionServer的 部署信息 、 并且存储有 meta表的位置信息
- HBase对于数据的读写操作时直接访问 Zookeeper的,
- 在 2.3版本 推 出 Master Registry模式,客户端可以直接访问 master。 使用此功能,会加大对 master的压力,减轻对 Zookeeper的压力。
HDFS:HDFS为 Hbase提供最终的底层数据存储服务,同时为 HBase提供高 容错 的支持。
Hbase被划分为多个分区(Region),用来横向切割和数据备份,实现分布式存储和备份
Region又按列族被划分为多个Store,相当于纵向切分,实现分布式存储和备份
每个Store对应一个MemStore写缓存,存储最新更新的数据
每个Store对应多个HFile(每次从MemStore中刷写就会产生一个HFile),用于持久化
快速入门
部署
部署Zookeeper
部署Hadoop
部署Hbase
Shell操作
进入客户端
bin/hbase shell
## 查看命名空间相关帮助
help
namespace相关
## 创建
create_namespace 'my_namespace'
## 查看
list_namespace
DDL
## 建表 --- 在my_namespace中新建表student,包含两个列族,info列族维护5个版本,msg列族默认维护1个版本
create 'my_namespace:student',{NAME => 'info',VERSIONS => 5},{NAME => 'msg'}
## 如果创建表格只有一个列族,没有列族属性,可以简写,如果不写命名空间,使用默认的命名空间 default
create 'student1','info'
## 查看所有表
list
## 查看单表详情
describe 'student'
## 修改表 --- 增加列族
alter 'my_namespace:student',{NAME => 'f1',VERSION => 3}
## 修改表 --- 删除列族
alter 'my_namespace:student',NAME => 'f1',METHOD => 'delete' ## 先修改method
alter 'my_namespace:student','delete' => 'f1' ## 后执行操作
## 删除表 --- 先禁用再删除
disable 'my_namespace:student'
drop 'my_namespace:student'
DML
## 写 --- 如果重复写入相同 rowKey,相同列的数据,会写入多个版本进行覆盖
put 'my_namespace:student','1001','info:name','张三'
put 'my_namespace:student','1001','info:name','lisi'
put 'my_namespace:student','1003','info:age','18'
## 读 --- 单条
get 'my_namespace:student','1001'
get 'my_namespace:student','1001',{COLUMN => 'info:name'}
get 'my_namespace:student','1001',{COLUMN => 'info:name',VERSION => 6}
## 读 --- 多条
scan 'my_namespace:student',{STARTROW => '1001',STOPROW => '1002'}
## 删除
delete 'my_namespace:student','1001','info:name' ## 默认删除最新版本
deleteall 'my_namespace:student','1001','info:name'
API操作
依赖
<dependencies>
<!--注意:会报错 javax.el包不存在,是一个测试用的依赖,不影响使用-->
<dependency>
<groupId>org.apache.hbase</
<artifactId>hbase server</artifactId>
<version> 2.4.11 </version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.1-b06</version>
</dependency>
</dependencies>
创建连接
根据官方API介绍, HBase的客户端连接由 ConnectionFactory类来创建,用户使用完成之后需要手动关闭连接。同时连接是一个重量级的,推荐一个进程使用一个连接,对 HBase的命令通过连接中的两个属性 Admin(用于DDL操作)和 Table(用于DML操作)来实现。
单线程创建连接
public class HBaseConnect {
public static void main(String[] args) throws IOException {
// 1. 创建配置对象
Configuration conf = new Configuration();
// 2. 添加配置参数
conf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104");
// 3. 创建 hbase 的连接
// 默认使用同步连接
Connection connection = ConnectionFactory.createConnection(conf);
// 可以使用异步连接
// 主要影响后续的 DML 操作
CompletableFuture<AsyncConnection> asyncConnection = ConnectionFactory.createAsyncConnection(conf);
// 4 . 使用连接
System.out.println(connection);
// 5. 关闭连接
connection.close();
}
}
多线程创建连接
public class HBaseConnect {
// 设置静态属性 hbase 连接
public static Connection connection = null;
static {
// 创建 hbase 的连接
try {
// 使用配置文件的方法
connection = ConnectionFactory.createConnection();
} catch (IOException e) {
System.out.println(" 连接 获取失败");
e.printStackTrace();
}
}
/**
* 连接关闭方法 用于进程关闭时调用
*
* @throws IOException
*/
public static void closeConnection() throws IOException {
if (connection != null) {
connection.close();
}
}
}
hbase-site.xml
<?xml version="1.0"?>
<?xml stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
</configuration>
DDL
创建 HBaseDDL类,添加静态方法即可作为工具类
public class HBaseDDL {
// 添加静态属性 connection 指向单例连接
public static Connection connection = HBaseConnect.connection;
}
创建命名空间
- admin 的连接是轻量级的 不是线程安全的 不推荐池化或者缓存这个连接
- 代码相对 shell 更加底层 所以 shell 能够实现的功能 代码一定能实现,所以需要填写完整的命名空间描述
public static void createNamespace(String namespace) throws IOException {
// 1. 获取 admin, 此处的异常先不要抛出 等待方法写完 再统一进行处理
Admin admin = connection.getAdmin();
// 2. 调用方法创建命名空间
NamespaceDescriptor.Builder builder = NamespaceDescriptor.create(namespace);
builder.addConfiguration("user", "atguigu"); // 给命令空间添加需求
try {
admin.createNamespace(builder.build());
} catch (IOException e) {
System.out.println("命令空间已经存在");
e.printStackTrace();
}
// 3. 关闭 admin
admin.close();
}
表存在校验
public static boolean isTableExists(String namespace, String tableName) {
// 获取admin
Admin admin = connection.getAdmin();
// 判断表存在
boolean b = false;
try {
b = admin.tableExists(TableName.valueOf(namespace, tableName));
} catch (Exception e) {
e.printStackTrace();
}
// 关闭admin
admin.close();
return true;
}
创建表
public static void createTable(String namespace,String tableName,String... columnFamilies) throws IOException{
// 判断是否至少需要一个列族
if(columnFamilies.length == 0){
System.out.println("至少需要一个列族");
return;
}
// 判断Table是否存在
if(isTableExists(namespace,tableName)){
System.out.println("Table 已存在");
return;
}
// 获取admin
Admin admin = connection.getAdmin();
// 创建表格
TableDescriptorBuilder tableDescriptorBuilder =
TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace,tableName));
// 添加参数
for(String columnFamilie: columnFamilies){
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder =
ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));
columnFamilyDescriptorBuilder.setMaxVersions(5); // 添加列族版本参数
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptorBuilder.build());
}
try{
admin.createTable(tableDescriptorBuilder.build());
}catch(IOException e){
e.printStackTrace();
}
// 关闭 admin
admin.close();
}
修改表
// 修改列族版本
public static void modifyTable(String namespace,String tableName,String columnFamily,int version) throws IOException{
// 判断Table是否存在
if(!isTableExists(namespace,tableName)){
System.out.println("Table 不存在");
return;
}
// 获取admin
Admin admin = connection.getAdmin();
try{
// 获取之前表描述
TableDescriptor descriptor = admin.getDescriptor(TableName.valueOf(namespace, tableName));
// 获取 TableDescriptorBuilder
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(descriptor);
// 获取之前的列族描述
ColumnFamilyDescriptor columnFamily1 = descriptor.getColumnFamily(Bytes.toBytes(columnFamily));
// 获取 ColumnFamilyDescriptorBuilder
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(columnFamily1);
// 修改列族描述信息
columnFamilyDescriptorBuilder.setMaxVersions(version);
// 修改表描述信息
tableDescriptorBuilder.modifyColumnFamily(columnFamilyDescriptorBuilder.build());
// 执行
admin.modifyTable(tableDescriptorBuilder.build());
}catch(IOException e){
e.printStackTrace();
}
// 关闭 admin
admin.close();
}
删除表
// 修改列族版本
public static boolean deleteTable(String namespace,String tableName) throws IOException{
// 判断Table是否存在
if(!isTableExists(namespace,tableName)){
System.out.println("Table 不存在");
return false;
}
// 获取admin
Admin admin = connection.getAdmin();
try{
TableName tableName1 = TableName.valueOf(namespace,tableName);
admin.disableTable(tableName1); // 置为不可用
admin.deleteTable(tableName1); // 删除
}catch(IOException e){
e.printStackTrace();
}
// 关闭 admin
admin.close();
return true;
}
DML
创建 HBaseDML类,添加静态方法即可作为工具类
public class HBaseDML {
// 添加静态属性 connection 指向单例连接
public static Connection connection = HBaseConnect.connection;
}
插入数据
public static void putCell(String namespace, String tableName, String rowKey,
String columnFamily, String columnName, String value) throws IOException {
// 获取 Table
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
// 创建 Put
Put put = new Put(Bytes.toBytes(rowKey));
// 添加数据
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName), Bytes.toBytes(value));
try {
// 执行
table.put(put);
} catch (Exception e) {
e.printStackTrace();
}
// 关闭
table.close();
}
读取数据
public static void getCells(String namespace, String tableName, String rowKey,
String columnFamily, String columnName) throws IOException {
// 获取 Table
Tabel table = connection.getTable(TableName.valueOf(namespace, tableName));
// 创建 Get
Get get = new Get(Bytes.toBytes(rowKey));
// 查询条件
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName));
get.readAllVersions();
try {
// 执行
Result result = table.get(get);
// 解析
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
String value = new String(CellUtil.cloneValue(cell));
System.out.println(value);
}
} catch (Exception e) {
e.printStackTrace();
}
table.close();
}
扫描数据
public static void scanRows(String namespace, String tableName, String startRow, String stopRow)
throws IOException {
Tabel table = connection.getTable(TableName.valueOf(namespace, tableName));
Scan scan = new Scan();
// 配置startRow、stopRow,否则扫描全表
scan.withStartRow(Bytes.toBytes(startRow));
scan.withStopRow(Bytes.toBytes(stopRow));
try {
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.print(new String(CellUtil.cloneRow(cell)) + "-"
+ new String(CellUtil.cloneFamily(cell)) + "-"
+ new String(CellUtil.cloneQualifier(cell)) + "-"
+ new String(CellUtil.cloneValue(cell)) + " t");
}
System.out.println();
}
} catch (Exception e) {
e.printStackTrace();
}
table.close();
}
过滤扫描
SingleColumnValueFilter --- 结果保留整行数据,同时会保留没有当前列的数据
public static void filterScan(String namespace, String tableName, String startRow,
String stopRow, String columnFamily,
String columnName, String value) throws IOException {
Tabel table = connection.getTable(TableName.valueOf(namespace, tableName));
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(startRow));
scan.withStopRow(Bytes.toBytes(stopRow));
// 可以添加多个过滤
FilterList filterList = new FilterList();
// 创建过滤器
// (1) 结果只保留当前列的数据
ColumnValueFilter columnValueFilter = new ColumnValueFilter(
Bytes.toBytes(columnFamily), // 列族名称
Bytes.toBytes(columnName), // 列名
CompareOperator.EQUAL, // 比较关系
Bytes.toBytes(value)); // 值
// (2) 结果保留整行数据 -- 与上述参数完全一致
// 结果同时会保留没有当前列的数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
Bytes.toBytes(columnFamily), // 列族名称
Bytes.toBytes(columnName), // 列名
CompareOperator.EQUAL, // 比较关系
Bytes.toBytes(value));// 值
filterList.addFilter(singleColumnValueFilter);
scan.setFilter(filterList);
try {
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.print(new String(CellUtil.cloneRow(cell)) + "-"
+ new String(CellUtil.cloneFamily(cell)) + "-"
+ new String(CellUtil.cloneQualifier(cell)) + "-"
+ new String(CellUtil.cloneValue(cell)) + " t");
}
System.out.println();
}
} catch (Exception e) {
e.printStackTrace();
}
table.close();
}
删除
public static void deleteColiumn(String namespace, String tableName, String rowKey,
String family, String column)
throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
// 创建Delete对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
// 删除单个版本
delete.addColumn(Bytes.toBytes(family), Bytes.toBytes(column));
// 删除所有版本
delete.addColumns(Bytes.toBytes(family), Bytes.toBytes(column));
// 删除列族
delete.addFamily(Bytes.toBytes(family));
// 执行
table.delete(delete);
table.close();
}
进阶
Master架构
Master:主要进程,具体实现类为HMaster,通常部署在nameNode上
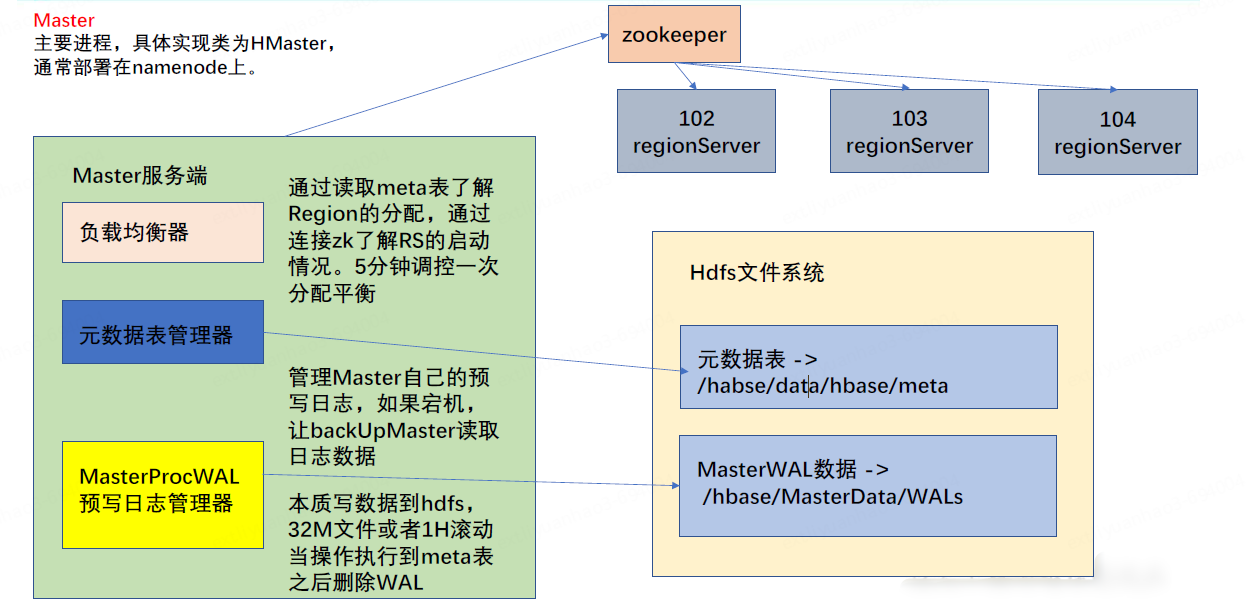
Master服务端
- LoadBalancer 负载均衡器:通过读取meta表了解Region的分配,通过zookeeper了解RegionServer的启动情况,默认5分钟调控一次分配平衡
- 元数据表管理器:管理Master自己的预写日志,如果宕机,让backUpMaster读取日志数据
- MasterProcWAL预写日志管理器:本质写数据到HDFS,32M文件或1H滚动当操作执行到meta表之后删除WAL
HDSF文件系统
- 元数据表 --- /hbase/data/hbase/meta
- MasterWAL数据 --- /hbase/MasterData/WALs
Meta表格:全称hbase:meta,只是在list命令中被过滤掉了,本质上和HBase其他表格一样
- RowKey:([table],[region start Key],[region id]) --- 即:表名,region起始位置,regionID
- 列:
- info:regioninfo为region信息,存储一个HRegionInfo对象
- info:server 当前region所处的RegionServer 信息,包含端口号
- info:serverstartcode 当前 region 被分到 RegionServer的起始时间
- 如果一个表处于切分的过程中,即region正在切分,还会多出两列,info:splitA 和 info:splitB,存储值也是HRegionInfo对象,拆分结束后删除这两列
在客户端对元数据进行操作时才会连接master,如果对数据读写,那么直接连接zookeeper读取目录/hbase/meta-region-serve节点信息,会记录meta表格的位置,直接读取即可,不需要访问master,这样可以减轻master的压力,相当于master专注meta表的写操作,客户端可直接读取meta表
在HBase的2.3版本更新了一种新的模式:Master Registry,客户端可以访问master来读取meta表信息,加大了master压力,减轻了zookeeper负担
RegionServer架构
RegionServer:主要进程,具体实现类为HRegionServer,通常部署在dataNode上
除了主要组件,还会启动多个线程监控一些必要的服务:
- Region拆分
- Region合并
- MemStore刷写
- WAL预写日志
MemStore写缓存:由于HFile(StoreFile)中的数据是有序的,所以需要先将数据存储到MemStore中,排好序后,等达到写时机才会刷到HFile中,每次刷写都会形成一个新的HFile,写到对应的文件夹store中
WAL预写日志:由于数据要经MemStore排序后才能刷到HFile,但把数据保存在内存中会有很高的概率会丢失,为了解决这个问题,数据会先到Write-Ahead logfile的文件中,然后再写入MemStore中,所以在系统出现故障的时候,数据可以通过这个日志文件重建
BlockCache读缓存:每次查询出的数据会缓存在BlockCache 中,方便下次查询
写流程
写流程顺序正如API编写顺序,首先创建HBase的重量级连接,之后使用创建的连接获取Table,这是轻量级的,只有在第一次创建Table连接的时候会检查表格是否存在而访问RegionServer,之后再获取Table时不会再访问RegionServer
先访问zookeeper,获取hbase:meta表位于哪个RegionServer
访问对应的RegionServer,获取hbase:meta表,将整张表缓存到连接中作为连接属性MetaCache,由于Meta表生产中比较大,导致创建连接比较慢
调用Table的put方法写入数据,此时还需要解析RowKey,对照缓存的MetaCache,查看具体写入的位置在哪个RegionServer
将数据顺序写入WAL,此处写入是直接落盘的,并设置专门的线程控制WAL预写日志的滚动(类似Flume)
根据写入命令的RowKey和ColumnFamily查看具体写入哪个MemStore,并且在MemStore中排序
向客户端发送ack
等待MemStore的刷写时机后,将数据写入对应的store中
MemStore Flush
MemStore刷写由多个线程控制,条件互相独立,
主要的刷写规则是控制文件大小
- 当某个MemStore的大小达到
hbase.hregion.memstore.flush.size(默认值 128M),其所在region的所有MemStore都会刷写, - 当
hbase.hregion.memstore.block.multiplier(默认值 4)时,会阻止继续往该 memstore写数据 (由于线程监控是周期性的,所有有可能面对数据洪峰,尽管可能性比较小)
- 当某个MemStore的大小达到
由HRegionServer中的属性MemStoreFlusher内部线程FlushHandler控制 --- LOWER_MARK(低水位线)和 HIGH_MARK(高水位线),意义在于避免写缓存使用过多的内存造成OOM
当region server中 memstore的总大小达到低水位线 ,Region会按照其所有MemStore的大小顺序(大 --> 小)依次进行刷写,直到RegionServer中所有MemStore的总大小减小到上述值以下
$java.heapsize × hbase.regionserver.global.memstore.size(默认值 0.4)× hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)$
当RegionServer中MemStore的总大小达到高水位线,会同时阻止继续 往所有的 memstore写数据。
$java.heapsize × hbase.regionserver.global.memstore.size(默认值 0.4)$
为了避免数据过长时间处于内存之中, 到达自动刷写的时间,也会触发 memstore flush。 由 HRegionServer的属性 PeriodicMemStoreFlusher控制进行,由于重要性比较低,5min才会执行一次,自动刷新的时间间隔由 该属性进行配置
hbase.regionserver.optionalcacheflushinterval(默认1小时)当 WAL文件的数量超过 hbase.regionserver.max.logs ,region会按照时间顺序依次进行刷写,直到 WAL文件数量减小到 hbase.regionserver.max.log以下 该属性名已经废弃,现无需手动设置 最大值为 32) ---- 基本不可能出现
HFile结构
HFile是存储在 HDFS上面每一个 store文件夹下实际存储数据的文件。里面存储多种内容。包括数据本身( keyValue键值对 )、元数据记录、文件信息、 数据索引 、元数据索引和一个固定长度的尾部信息(记录文件的修改情况)
键值对按照块大小(默认 64K)保存在文件中 数据索引 按照块 创建,块越多,索引越大。 每一个 HFile还会维护一个 布隆过滤器 就像是一个很大的地图,文件中每有一种 key就在对应的位置标记,读取时可以大致判断要 get的 key是否存在 HFile中
keyValue内容如下:
- rowlength --- key长度
- row ---- key的值
- columnfamilylength --- 列族长度
- columnfamily --- 列族
- columnqualifier --- 列名
- timestamp --- 时间戳(系统默认时间)
- keytype --- put、delete
由于HFile存储经过序列化,无法直接查看,可以通过命令查看元数据内容
hbase -m -f /hbase/data/命名空间/regionID/列族/HFile名
读流程
创建连接和写流程一样
- Client先访问Zookeeper,获取hbase:meta表位于哪个Region Server。
- 访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标Region Server进行通讯;
- 分别在Block Cache(读缓存),MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
- 将从文件中查询到的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
- 将合并后的最终结果返回给客户端。
每次读取数据都需要读取三个位置,最后进行版本的合并。效率会非常低,所有系统需要对此优化
- HFile带有索引文件,读取对应RowKey数据比较快
- BlockCache会缓存之前读取的内容和元数据,如果HFile没有变化(HFile尾信息),则不需要再次读取
- 使用布隆过滤器能够快速过滤当前HFile不存在需要读取的RowKey,从而避免读取文件
StoreFile Compaction
由于memstore 每次刷写都会生成一个新的HFile,文件过多读取不方便,所以会进行文件的合并,清理掉过期和删除的数据,会进行StoreFile Compaction
Compaction 分为两种,分别是Minor Compaction 和Major Compaction。
Minor Compaction会将临近的若干个较小的HFile 合并成一个较大的HFile,并清理掉部分过期和删除的数据, 有系统使用一组参数自动控制,参与到小合并的文件需要通过参数计算得到,有效的参数有5 个
- hbase.hstore.compaction.ratio(默认1.2F)合并文件选择算法中使用的比率。
- hbase.hstore.compaction.min(默认3) 为Minor Compaction 的最少文件个数。
- hbase.hstore.compaction.max(默认10) 为Minor Compaction 最大文件个数。
- hbase.hstore.compaction.min.size(默认128M)为单个Hfile 文件大小最小值,小于这个数会被合并。
- hbase.hstore.compaction.max.size(默认Long.MAX_VALUE)为单个Hfile 文件大小最大值,高于这个数不会被合并。
小合并机制为拉取整个store 中的所有文件,做成一个集合。之后按照从旧到新的顺序遍历。判断条件为:
- 过小合并,过大不合并
- 文件 大小 / hbase.hstore.compaction.ratio < (剩余文件 大小和 ) 则参与压缩。所有把比值设置过大,如 10会最终合并为 1个特别大的文件,相反设置为 0.4,会最终产生 4个 storeFile。不建议修改默认值
- 满足压缩条件的文件个数达不到个数要求( 3 <= count <= 10)则不压缩。
Major Compaction 会将一个Store 下的所有的HFile 合并成一个大HFile,并且会清理掉所有过期和删除的数据,由参数hbase.hregion.majorcompaction控制,默认7 天
Region Split
Region切分分为两种,创建表格时候的预分区即自定义分区,同时系统默认还会启动一个切分规则,避免单个 Region中的数据量太大。
预分区(自定义分区):每一个region维护着 startRow与 endRowKey,如果加入的数据符合某个 region维护的 rowKey范围,则该数据交给这个 region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高 HBase性能。
手动设定
create 'staff1','info', SPLITS => ['1000','2000','3000','4000']默认设定(16进制)
create 'staff2','info', {NUMREGIONS => 15, SPLITALGO => ’HexStringSplit'}根据文件设定
create 'staff3' info ',SPLITS_FILE => 'splits.aaaa bbbb cccc ddddAPI 创建
public static void splitRegion(String tableName,String splitName,String columnFamily,String... splitValue) throws IOExceptio // 获取配置类 Configuration conf = HBaseConfiguration.create(); // 添加配置 conf.set(conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104"); // 获取连接 Connection connection = ConnectionFactory.createConnection(conf); // 获取 admin Admin admin = connection.getAdmin(); // 获取descriptor的Builder TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName,splitName)); // 添加列族 builder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)).build()); // 创建对应切分 byte[][] splits = new byte[splitValue.length][]; for (int i = 0; i < splits.length; i++) { splits[i] = Bytes.toBytes(splitValue[i]); } // 创建表 admin.createTable(builder.build(),splits); // 关闭资源 admin.close(); connection.close(); }
系统拆分(默认拆分):Region的拆分是由 HRegionServer完成的
- 在操作之前需要通过 ZK汇报 master,修改对应的 Meta表信息添加 两列 info splitA和 info splitB信息 。
- 之后需要操作 HDFS上面对应的文件,按照拆分后的 Region范围进行标记区分, 实际操作为创建文件引用,不会挪动数据。
- 刚完成拆分的时候, 两个 Region都由原先的 RegionServer管理 。
- 之后汇报给 Master,由 Master将修改后的信息写入到 Meta表中。
- 等待下一次触发负载均衡机制,才会修改 Region的管理服务者,而 数据要等 到下一次压缩时,才会实际进行移动 。
不管是否使用预分区系统都会默认启动一套 Region拆分规则 。 不同版本的拆分规则有差别。系统拆分策略的父类为 RegionSplitPolicy
- 0.94版本之前 => ConstantSizeRegionSplitPolicy:当 1个 region中的某个 Store下所有 StoreFile的总大小超过hbase.hregion.max.filesize (10G),该 Region就会进行拆分
- 0.94版本之后, 2.0版本之前 => IncreasingToUpperBoundRegionSplitPolicy:当 1个 region中的某个 Store下所有 StoreFile的总大小超过
Min(initialSize*R^3 ,hbase.hregion.max)该 Region就会进行拆分 。 其中 initialSize的默认值为 2*hbase.hregion.memstore.flush.size ,R为当前 Region Server中属于该 Table的Region个数( 0.94版本之后)。具体的切分策略为:- 第一次:split 1^3 * 256 = 256MB
- 第二次:split 2^3 * 256 = 2048MB
- 第三次:split 3^3 * 256 = 6912MB
- 第四次:split 4^3 * 256 = 16384MB > 10GB,因此取较小的值 10GB
- 后面每次split的 size都是 10GB
- 2.0版本之后 => SteppingSplitPolicy:Hbase 2.0引入了新的 split策略:如果当前 RegionServer上 该 表只有一个 Region按照 2 * hbase.hregion.memstore.flush.size分裂,否则按照 hbase.hregion.max.filesize分裂。
优化
RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于 rowkey处于哪个一个预分区的区间内,设计 rowkey的主要目的 ,就是让数据均匀的分布于所有的 region中,在一定程度上防止数据倾斜。
- 生成随机数、hash、散列值
- 时间戳反转
- 字符串拼接
需求:使用hbase 存储下列数据,要求能够通过hbase 的API 读取数据完成两个统计需求。
1、统计张三在2021 年12 月份消费的总金额
2、统计所有人在2021 年12 月份消费的总金额
实现
为了能够统计张三在2021 年12 月份消费的总金额,我们需要用scan 命令能够得到张三在这个月消费的所有记录,之后在进行累加即可。Scan 需要填写startRow 和stopRow:
startRow -> ^A^Azhangsan2021-12 endRow -> ^A^Azhangsan2021-12.- 避免扫描数据混乱,解决字段长度不一致的问题,可以使用相同阿斯卡码值的符号进行填充,框架底层填充使用的是阿斯卡码值为1 的^A
- 最后的日期结尾处需要使用阿斯卡码略大于’-’(45)的值,常用‘.’(46)
- 最终得到rowKey的设计为 -----
user:date( yyyy-MM-dd HH:mm:SS)
对应需求2,用上述方法就没办法写rowKey范围
rowkey设计特点:适用性强,泛用性差,能够完美实现一个需求,但是不能同时完美实现多个需要
调整原则:可枚举的放前面
最终设计为 ---
date(yyyy-MM)^A^A:userdate(-dd hh:mm:ss ms)需求1
startRow => 2021-12^A^Azhangsan stopRow => 2021-12^A^Azhangsan.需求2
startRow => 2021-12 stopRow => 2021-12.
预分区优化
预分区的分区号同样需要遵守rowKey的 scan原则。所有必须添加在 rowKey的最前面,前缀为最简单的数字。同时使用 hash算法将用户名和月份拼接决定分区号。(单独使用用户名会造成单一用户所有数据存储在一个分区)
startKey stopKey
001
001 002
002 003
...
119 120
分区号 => hash(user+date(MM)) % 120
分区号填充 如果得到 1 => 001
最终得到rowKey 设计格式 => 分区号:date(yyyy-MM)^A^A:userdate(-dd hh:mm:ss ms)
实现需求 2的时候,由于每个分区都有 12月份的数据,需要扫描 120个分区。存数据的时候需要提前将月份和分区号对应一下
000 到 009 分区 存储的都是 1 月份数据
010 到 019 分区 存储的都是 2 月份数据
...
110 到 119 分区 存储的都是 12 月份数据
存储9月份的数据
分区号 => hash(user+date(MM)) % 10 + 80
分区号填充 如果hash得到 85 => 085
获取12月份所有人的数据 --- 扫描 10 次
startRow => 1102021-12
stopRow => 1102021-12.
...
startRow => 1122021-12
stopRow => 1122021-12.
...
...
startRow => 1192021-12
stopRow => 1192021-12.
参数优化
hbase-site.xml
Zookeeper相关
zookeeper.session.timeout ---- 会话超时时间,默认值为 90000 毫秒( 90s )
当某个 RegionServer 挂掉,90s 之后 Master 才能察觉到。可适当减小此值, 尽可能快地检测 regionserver 故障 ,可调整至 20-30 s 。
hbase.client.pause ---- 重试时间(默认值 100 ms)
hbase.client.retries.number ---- 重试次数(默认 15 次)
hbase.regionserver.handler.count ---- RPC 监听数量,默认值为 30
用于指定 RPC 监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值
hbase.hregion.majorcompaction ---- 手动控制 Major Compaction,默认值: 604800000 秒( 7 天)
Major Compaction 的周期,若关闭自动 MajorCompaction ,可将其设为 0 。 如果关闭一定记得自己手动合并,因为大合并非常有意义
hbase.hregion.max.filesize ---- 优化 HStore 文件大小,默认值 10737418240 (10 GB)
如果需要运行 HBase 的 MR 任务,可以减小此值,因为一个 region 对应一个 map 任务,如果单个 region 过大,会导致 map 任务执行时间过长。该值的意思就是,如果 HFile 的大小达到这个数值,则这个 region 会被切分为两个Hfile
hbase.client.write.buffer ---- 优化 HBase 客户端缓存,默认值 20 97152 bytes (2M)
用于指定 HBase 客户端缓存,增大该值可以减少 RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少 RPC 次数的目的。
hbase.client.scanner.caching ---- 指定 scan.next 扫描 HBase 所获取的行数
用于指定 scan .next 方法获取的默认行数,值越大,消耗内存越大。
hfile.block.cache.size ---- BlockCache 占用 RegionServer 堆内存的比例,默认 0.4
读请求比较多的情况下,可适当调大
hbase.regionserver.global.memstore.size ---- 默认 0.4
写请求较多的情况下,可适当调大
JVM调优
JVM调优的思路有两部分:一是内存设置,二是垃圾回收器设置。
垃圾回收的修改是使用并发垃圾回收,默认 PO+PS是 并行 垃圾回收 ,会有大量的暂停 。理由是 HBsae大量使用内存用于存储数据,容易遭遇数据洪峰造成 OOM,同时写缓存的数据是不能垃圾回收的,主要回收的就是读缓存,而读缓存垃圾回收不影响性能
## 使用CMS收集器 -XX:+UseConMarkSweepGC ## 在内存占用到 70% 的时候开启 GC -XX:CMSInitiatingOccupancyFraction=70 ## 指定使用 7 0 %%,不让 J VM 动态调整 -XX:+UseCMSInitiatingOccupancyOnly ## 新生代内存设置为 512 m -Xmn512m ## 并行执行新生代垃圾回收 -XX:+UseParNewGChbase-site.xml
hbase.client.scanner.max.result.size ---- scanner 扫描结果占用内存大小,默认值为 2 M
设置为 eden 空间的 1/8(大概在 64M),设置多个与 max.result.size * handler.count 相乘的结果小于 Survivor Space (新生代经过垃圾回收之后存活的对象)
经验法则
官方给出了权威的使用法则:
- Region大小控制 10-50G
- cell大 小不超过 10M(性能对应小于 100K的值有优化),如果使用 mob Medium-sized Objects一种特殊用法)则不超过 50M。
- 1张表有 1到 3个列族,不要设计太多。 最好就 1个,如果使用多个尽量保证不会同时读取多个列族。
- 1到 2个列族的表格,设计 50-100个 Region。
- 列族名称要尽量短,不要去模仿 RDBMS(关系型数据库)具有准确的名称和描述。
- 如果 RowKey设计时间在最前面,会导致有大量的旧数据存储在不活跃的 Region中,使用的时候,仅仅会操作少数的活动 Region,此时建议增加更多的 Region个数。
- 如果只有一个列族用 于写入数据,分配内存资源的时候可以做出调整,即写缓存不会占用太多的内存。
整合Phoenix
Phoenix是 HBase的开源 SQL皮肤。可以使用标准 JDBC API代替 HBase客户端 API来创建表,插入数据和查询 HBase数据。
官方给的解释为:在Client和 HBase之间放一个 Phoenix中间层不会减慢速度,因为用户编写的数据处理代码和Phoenix编写的没有区别( 更不用说你写的垃圾的多 ),不仅如此Phoenix对于用户输入的 SQL同样会有大量的优化手段(就像 hive自带 sql优化器一样)。
Phoenix在 5.0版本默认提供有两种客户端使用(瘦客户端和胖客户端),在 5.1.2版本安装包中删除了瘦客户端,本文也不再使用瘦客户端。而胖客户端和用户自己写 HBase的API代码读取数据之后进行数据处理是完全一样的。
安装
出现下面错误的原因是之前使用过phoenix,建议删除之前的记录
警告 : Failed to load history
java.lang.IllegalArgumentException: Bad history file syntax! The
history file `/home/atguigu/.sqlline/history` may be an older
history: please remove it or use a different history file.
解决方法:在/home/atguigu目录下删除 .sqlline文件夹
rm rf .sqlline/
shell操作
关于Phoenix的语法建议使用时直接查看官网
显示表
!table 或 !tables
创建表
- 表名等会自动转换为大写,若要小写,使用双引号,如 "us_population"
- 为了减少数据对磁盘空间的占用, Phoenix默认会对 HBase中的列名做编码处理。具体规则可参考官网链接,若不想对列名编码,可在建表语句末尾加上 COLUMN_ENCODED_BYTES = 0;
-- 指定单列RowKey
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
age BIGINT,
addr VARCHAR);
-- 指定多列RowKey
CREATE TABLE IF NOT EXISTS student1(
id VARCHAR NOT NULL,
name VARCHAR NOT NULL,
age BIGINT,
addr VARCHAR
CONSTRAINT my_pk PRIMARY KEY ( id , name));
删除表
drop table student;
插入数据
- 独创upsert,相当于mysql的update和insert结合,用于执行hbase的put命令
upsert into student values('1001', zhangsan ,10 ,'beijing');
查询
select * from student;
select * from student where id='1001';
删除
delete from student where id='1001';
退出命令行
!quit
表映射
默认情况下,HBase中已存在 的表,通过 Phoenix是 不可见 的。如果要在 Phoenix中操作 HBase中 已存在 的表, 可以 在 Phoenix中进行表的映射。映射方式有两种:视图映射和表映射
如:对test表做映射,两个列族info1对应name,info2对应address
视图映射:Phoenix创建的视图是 只读 的,所以只能用来做查询,无法通过视图对数据进行修改等操作。在 phoenix中创建 关联 test表的视图
--- 创建视图 create view "test"( id varchar primary key, "info1"."name" varchar, "info2"."address" varchar); --- 删除视图 drop view "test";表映射:在Pheonix创建表去映射 HBase中已经存在的表,是可以修改删除 HBase中已经存在的数据的。而且,删除 Phoenix中的表,那么 HBase中被映射的表也会被删除。进行表映射时,不能使用列名编码,需将column_encoded_bytes设为 0
create table "test"( id varchar primary key, "info1"."name" varchar, "info2"."address" varchar) column_encoded_bytes=0;
数据类型说明:HBase中的数字,底层存储为补码,而 Phoenix中的数字,底层存储为在补码的基础上,将符号位反转。故当在 Phoenix中建表去映射 HBase中已存在的表,当 HBase中有数字类型的字段时,会出现解析错误的现象
Phoenix种提供了 unsigned_int unsigned_long等无符号类型,其对数字的编码解码方式和 HBase是相同的,如果无需考虑负数,那在 Phoenix中建表时采用无符号类型是最合适的选择。
如需考虑负数的情况,则可通过 Phoenix自定义函数,将数字类型的最高位,即符号位反转即可,自定义函数可参考如下链接: https://phoenix.apache.org/udf.html
JDBC操作
依赖
需要去掉原有的hbase依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-client-hbase-2.4</artifactId>
<version>5.1.2</version>
</dependency>
代码
@Test
public void testPhoenix() {
// 标准JDBC代码
// 添加url
String url = "jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
// 创建配置 ---- 没有账号密码,不用设置
Properties properties = new Properties();
// 获取连接
Connection connection = DriverManager.getConnection(url, properties);
// 编译SQL
PreparedStatement preparedStatement = connection.prepareStatement("select * from student");
// 执行
ResultSet resultSet = preparedStatement.executeQuery();
// 解析结果
while (resultSet.next()) {
System.out.println(resultSet.getString(1) + ":" +
resultSet.getString(2) + ":" + resultSet.getString(3));
}
// 关闭资源
connection.close();
// 由于 Phoenix 框架内部需要获取一个 HBase 连接 所以会延迟关闭
// 不影响后续的代码执行
System.out.println("hello");
}
二级索引
配置
hbase site.xml
phoenix regionserver 配置参数
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
全局索引
Global Index是 默认的索引格式 ,创建全局索引时,会在 HBase中建立一张新表 。
也就是说索引数据和数据表是存放在不同的表中的,因此全局索引 适用于 多读少写 的业务场景。
写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。
创建 与 删除
create index my_index on student1(age); drop index my_index on student1;查看
explain select id,name from student1 where age = 10;
包含索引
创建携带其他字段的全局索引 (本质还是全局索引) 。相当于mysql的联合(聚簇)索引
创建
create index my_index on student1(age) include (addr);
本地索引
Local Index适用于写操作频繁的场景。
索引数据和数据表的数据是存放在同一张表中(且是同一个 Region)),避免了在写操作的时候往不同服务器的索引表中写索引 带来的额外开销
本地索引会将所有的信息存在一个影子列族中,虽然读取的时候也是范围扫描 ,但是没有全局索引快,优点在于索引信息不用写多个表了。
创建 --- my_column可以是多个
CREATE LOCAL INDEX my_index ON my_table (my_ column); CREATE LOCAL INDEX my_index ON student1 (age,addr);
Hive集成
如果大量的数据已经存放在 HBase上面,需要对已经存在的数据进行数据分析处理,那么 Phoenix并不适合做特别复杂的 SQL处理,此时可以使用 hive映射 HBase的表格,之后写 HQL进行分析处理。
在hive-site.xml中 添加 zookeeper的属性,如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</name>
</property>
案例1:建立 Hive表,关联 HBase表,插入数据到 Hive表的同时能够影响 HBase 表
在Hive中创建表,同时关联HBase
CREATE TABLE hive_hbase_emp_table( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:co mm,info:deptno") TBLPROPERTIES ("hbase.table.nam e" = "hbase_emp_table");完成之后,可以分别进入 Hive和 HBase查看,都生成了对应的表
在 Hive中创建临时中间表,用于 load文件中的数据,不能将数据直接 load进 Hive所关联 HBase的那张表中
CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by '\t';向 Hive中间表中 load数据
load data local inpath '/ opt /software emp.txt' into table emp;通过 insert命令将中间表中的数据导入到 Hive关联 Hbase的那张表中
insert into table hive_hbase_emp_table select * from emp;查看 Hive以及关联的 HBase表中是否已经成功的同步插入了数据
select * from hive_hbase_emp_table;scan 'hbase_emp_table'
案例2:在 HBase中已经存储了某一张表 hbase_emp_table,然后在 Hive中创建一个外部表来关联 HBase中的 hbase_emp_table这张表,使之可以借助 Hive来分析 HBase这张表中的数据。
先完成案例1
在 Hive中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHander' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info :ename,info:job,info:mgr,info:hiredate,info:sal,info:co mm,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");关联后就可以使用 Hive函数进行一些分析操作了
select deptno,avg(sal) monery from relevance_hbase_emp group by deptno ;